如何设计一个短网址服务
短网址问题
短网址服务相信大家都用过,核心的功能就是将原始的长网址转化成长度更短的短网址,当我们访问这个短网址的时候最终会跳转到这个原始的长网址所指向的位置。
那么我们今天的问题就是设计一个短网址服务(TinyURL)
如何设计
看起来这个问题不需要太多的沟通,但实际上仔细想想会发现这样的需求描述离开始动手还是有一段距离。
下面我们开始着手从不确定和模糊的条件动手,一步步完成这个系统设计。
第一步:沟通、澄清问题
先从功能需求开始:
功能的部分相对比较清晰,包括操作的两个阶段:
- 原始URL转化成 TinyURL
- TinyURL反向转化为原始URL
其实作为一个完整的商业产品还会有其他的功能需求,比如:
- 运营数据统计
- 定制化域名
- 保留部分Path前缀
……
限于篇幅、和简化问题的原因,我们本次的系统设计只涉及这个服务的最核心功能。
其次从非功能的角度来看,有如下需求:
- 系统高性能 - 特别是TinyURL转换为原始URL的部分,这部分多数应用场景是用在最终用户端的,如果跳转时间、白屏时间较长的话可能会有不好的产品体验。
- 系统高可用 - 还是希望该系统能够持续提供稳定服务。
聊完了需求部分,我们来看下系统的规模和所需要支持环境的信息。
我们假设给微博来设计一个这样的系统,与之匹配的会是这样的一些数据:
DAU: 1亿
日新增微博数:2亿
新增微博中带连接的比例: 40%
带链接新增微博中使用TinyURL的比例: 50%
系统读写比:9:1
系统API日访问数:20亿
根据上面的基础数据可以简单推算下一些性能相关的数据:
API日访问数 20亿,那么平均到秒就是
$$QPS = 2000000000 / (24 * 60 * 60) \approx 20000$$
当然,这样的平均计算不太科学,毕竟产品的使用在时间上并不是均匀分布的,所以这里QPS的计算我们需要在这个平均值上乘以一个系数,来符合大多数时间的性能指标,这里假设系数为10是比较合理的,所以我们就有了系统的第一个目标性能指标:
$$QPS = 20w$$
日产生数据量:
$$日产生TinyURL数量 = 2亿0.4 0.5 = 4kw $$
假设原始的URL平均长度为100Byte, TinyURL的平均长度为20Byte,再加上主键的长度int(11) 也就是 $11 * 4 = 44Byte$, 那么一条数据不考虑数据压缩的情况下,需要的存储空间会是 164Byte, 那么日产生的新增数据存储规模是 $4kw * 164Byte \approx 40*164 MByte \approx 7GByte$ 一年内数据存储规模会是 $7G * 360 \approx 2.8T$ 这样的一个单表量级尚未达到MySQL和Linux操作系统单文件大小限制(16TB - EXT4 on RHEL What are the file and file system size limitations for Red Hat Enterprise Linux?)
所以,在这个维度上MySQL(Oracle)这样的关系型数据库是能够胜任的,只不过数据发展到必要的时期需要做一些数据库上的技术改造(Sharding or Partitioning)
第一阶段产物
用例
| 需求类型 | 需求描述 |
|---|---|
| 功能需求 | 原始URL转化成 TinyURL |
| TinyURL反向转化为原始URL | |
| 非功能需求 | 高性能 |
| 高可用 |
设计约束
| 设计约束 | 指标 |
|---|---|
| QPS | 20w |
| 读写比 | 9:1 |
| 数据存储年增长规模 | 2.8TB |
第二步:抽象模型
应用相对简单,在High-level的设计中系统架构上就简单将架构分为两层,应用层和数据持久层。当然,考虑到系统需要高可用的非功能性需求,直接的想法就是在应用实例上增加负载均衡,再考虑到读取操作的性能要求(并且考虑到读写比较高的实际条件),可以考虑在应用层与持久层之间添加cache,提升查询效率。
于是便有了以下的系统架构图: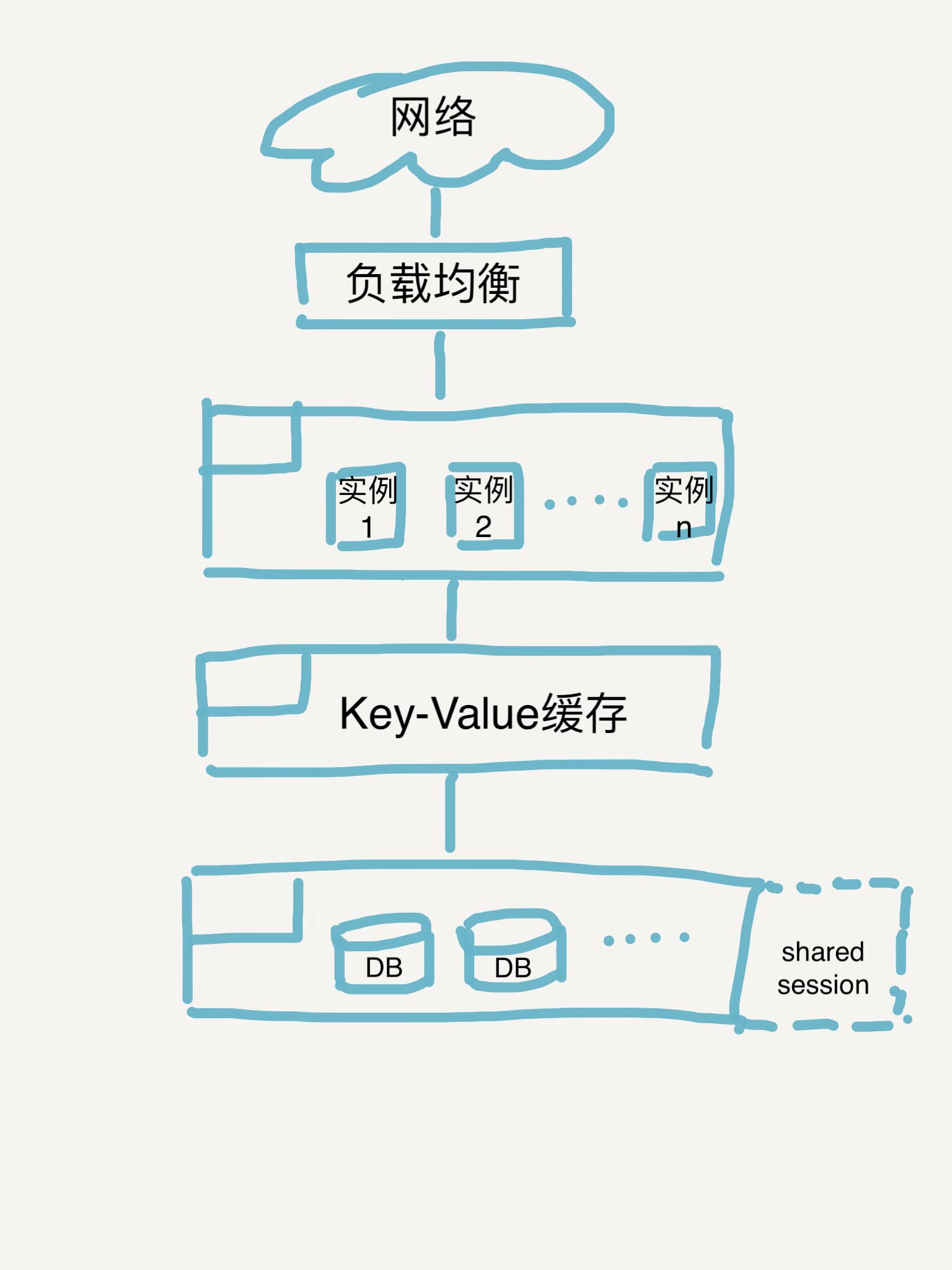
其实这个设计依然存在着单点故障的风险,就是负载均衡部分本身,在综合了成本和改造难度等因素后依然决定消除这个单点故障,可行的方案是:多数据中心负载。
系统架构就演进成为下面的这样: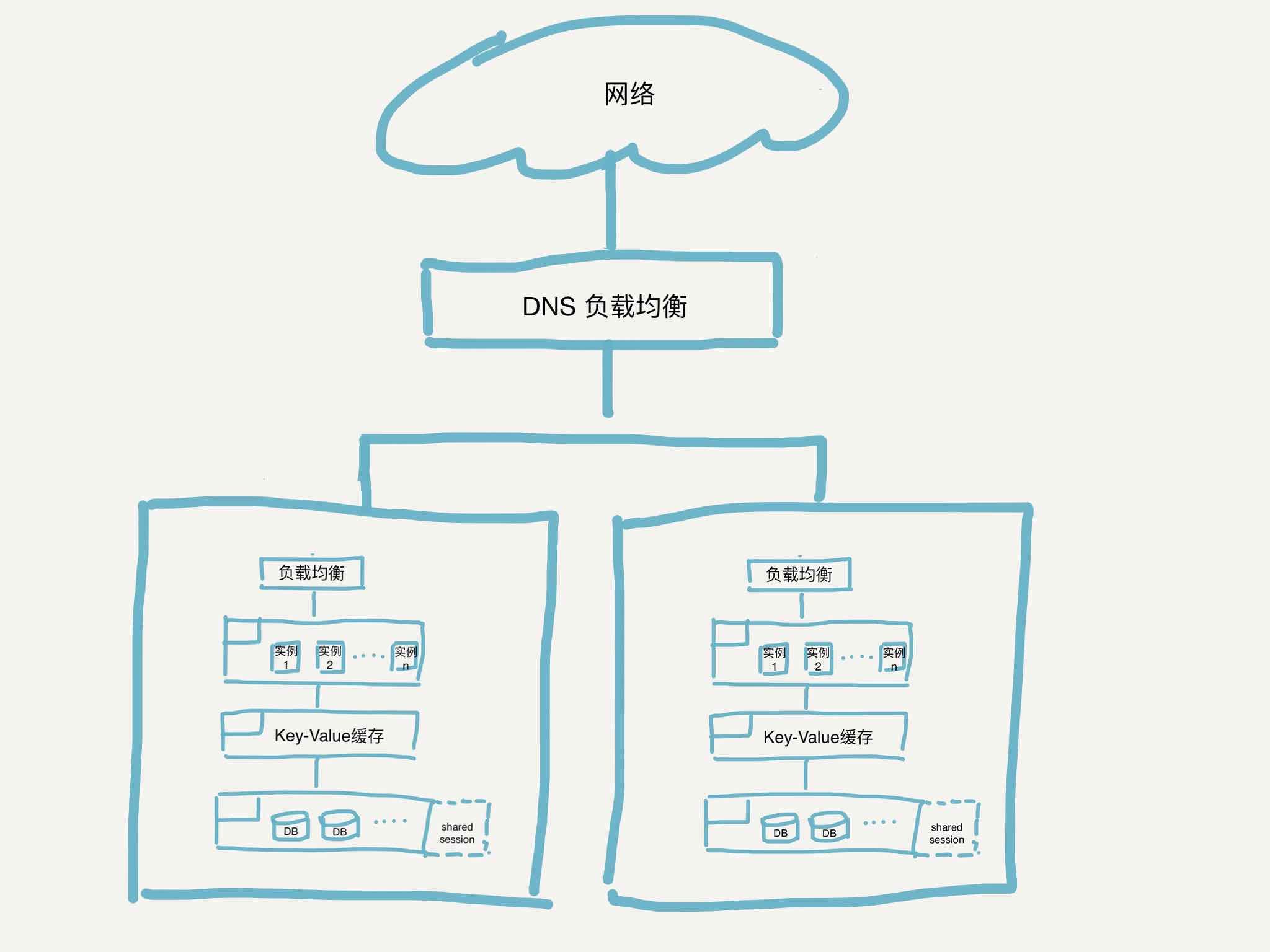
DNS的负载均衡我们可以选择高可用的解决方案;
key-Value的缓存我们可以考虑使用Redis 中的String数据结构;
数据库我们可以使用AP的No-SQL(Key-Value)数据库 Dynamo
第二阶段产物
考虑到新的技术栈的引入,以及系统复杂度的提高,最终还是决定实现第一个单数据中心的架构方案。
单数据中心方案中的持久层我们就可以使用MySQL这样关系型数据库,如果考虑有读压力的问题,可以使用Leader-follower结构的数据库结构。
系统设计图
第三步:关键组件设计
第三阶段产物
表结构设计
核心功能表,t_url_mapping
1 | CREATE TABLE IF NOT EXISTS t_url_mapping ( |
对外接口设计
- 原始URL转TinyURL
GET /tiny/
1 | { |
关键组件核心算法设计
问题Leetcode描述:
Encode and Decode TinyURL
1 | public class Codec { |
其实核心的算法需要解决的问题是,选择一个高效的Hash算法,完成对原始URL和TinyURL的映射。
关于Hash算法的问题,有两个关键问题:
- hash 函数的选择
- hash 冲突的处理
这里有两种思路:
一种是使用现成的Hash函数,在使用现成算法的基础上处理Hash冲突,然后将这个10进制数转化为62位后,得到的字符就是缩短后的短网址。
另外一种思路是使用ID生成器,自己维护一个自增的ID生成器,给每个原始URL分配一个ID,然后这个ID经过62位转化后就会变成长度变短的短网址。
我们先用第一个思路来实现:
1 |
|
这里有一个技术处理的小技巧:在使用JDK String 的hashcode时,hashcode可能会返回小于0的负数,在10进制转62进制的算法中我们是假定输入参数为正数,所以这里通过 一个位操作 消去整数的符号位。
作为完整的解决方案,应当考虑对应的单元测试;
特别是10进制转62进制的转换方法,稍微延展一下就可以用在邀请码等常用业务场景。
测试部分可参考 Github algorithmPlayground
